分布式文件系統(tǒng)
發(fā)布時間:
2022-03-30 13:38:38
Google公司的三駕馬車GFS�����、Bigtable和MapReduce經(jīng)常被大家看作是云計算的經(jīng)典之作��,Amazon公司的Dynamo和開源項目Hadoop也是云計算世界里的明星產(chǎn)品,實際上從技術(shù)角度來看它們都屬于分布式系統(tǒng)的范疇�����。
分布式文件系統(tǒng)是如何發(fā)展起來的呢?
從20世紀(jì)70年代誕生至今����,大致上可以將分布式文件系統(tǒng)的發(fā)展歷程劃分為四個階段。1990年之前的分布式文件系統(tǒng)主要以提供標(biāo)準(zhǔn)接口的遠程文件訪問為目的�����,比較關(guān)注系統(tǒng)性能和可靠性���。這一階段的典型代表包括Sun公司研制的NFS(NetworkFile System)和美國卡內(nèi)基梅隆大學(xué)開發(fā)的AFS(Andrew File System)���。
1990年到1995年期間,互聯(lián)網(wǎng)逐步得到推廣應(yīng)用����,網(wǎng)絡(luò)中傳輸實時多媒體數(shù)據(jù)的需求和應(yīng)用也逐漸流行�,這一階段出現(xiàn)了不少為了實現(xiàn)上述需求而開發(fā)設(shè)計的分布式文件系統(tǒng)�����,例如加利福尼亞大學(xué)研制的xFS(x File System)和IBM公司針對AIX操作系統(tǒng)開發(fā)的TigerShark����。
1995年到2000年期間,網(wǎng)絡(luò)技術(shù)和存儲技術(shù)持續(xù)發(fā)展���,NAS和SAN等新的存儲技術(shù)開始得到大量應(yīng)用��,與之相應(yīng)的分布式文件系統(tǒng)也應(yīng)運而生��,例如美國明尼蘇達大學(xué)研制的GFS(Global File System)和IBM公司在TigerSpark基礎(chǔ)上開發(fā)的GPFS(General Parallel File System)�����。
進入21世紀(jì)以來��,隨著網(wǎng)格計算和云計算技術(shù)的發(fā)展���,以Google公司為代表的軟件公司和研究機構(gòu)針對Web應(yīng)用的特色����,陸續(xù)推出了新型的分布式文件系統(tǒng)�����。這其中最為著名的當(dāng)屬Google公司的GFS(Google File System)和Hadoop開源項目的HDFS(Hadoop Distributed File System)����。
注意上面提到了兩個GFS�,一個是明尼蘇達大學(xué)研制的Global File System,另一個是Google公司開發(fā)的Google File System����,后續(xù)我們提到的GFS都是特指后者,不再專門說明�����。
看起來�����,好像進入21世紀(jì)之后的分布式文件系統(tǒng)才與云計算產(chǎn)生了交集�,是這樣嗎?
應(yīng)該說���,GFS和HDFS都是在云計算時代應(yīng)運而生的產(chǎn)物,它們與傳統(tǒng)的分布式文件系統(tǒng)有很大的不同��,更能夠滿足云計算的需求����。
但是,GFS的新穎之處并不在于它采用了多么令人驚訝的新技術(shù)����,而在于它采用廉價的商用計算機集群構(gòu)建分布式文件系統(tǒng),在降低成本的同時經(jīng)受了實際應(yīng)用的考驗��。
與傳統(tǒng)的分布式文件系統(tǒng)相比�,GFS有哪些新的設(shè)計需求呢?
在性能、伸縮性�、可靠性等方面,GFS的設(shè)計目標(biāo)與傳統(tǒng)的分布式文件系統(tǒng)沒有什么區(qū)別;但是考慮Google各種應(yīng)用的實際情況后�����,GFS在許多方面的設(shè)計目標(biāo)又具有鮮明的特色����。這主要體現(xiàn)在下述方面���。
(1)Google的數(shù)據(jù)中心均采用廉價的計算機和IDE硬盤構(gòu)建,因此硬件故障是一種常見的狀況�����,在軟件設(shè)計上必須提高容錯能力���。
(2)系統(tǒng)需要處理數(shù)以百萬計的文件�,大多數(shù)是100MB或更大�����,其中出現(xiàn)GB級別的文件也不奇怪��,必須在設(shè)計時充分考慮這些因素��。
(3)系統(tǒng)主要考慮支持兩種讀操作:大規(guī)模數(shù)據(jù)流讀和小規(guī)模隨機讀����。前者通常連續(xù)讀取1MB或更多數(shù)據(jù)�����,后者通常讀取幾kB數(shù)據(jù)。
(4)系統(tǒng)中存在兩種寫操作:大規(guī)模順序?qū)懞托∫?guī)模隨機寫�。前者通常連續(xù)寫入1MB或更多數(shù)據(jù),需要在設(shè)計時考慮性能優(yōu)化�����。
(5)經(jīng)常會出現(xiàn)多個應(yīng)用程序同時向同一個文件進行追加寫操作�����,必須保證這些并發(fā)操作的正確性���。
(6)希望系統(tǒng)在針對大數(shù)據(jù)量操作時獲得高性能�����,不關(guān)注單個讀寫操作所花費的時間���。
GFS為應(yīng)用程序提供了哪些訪問接口?
GFS提供了一個類似傳統(tǒng)文件系統(tǒng)的接口,按照層次型的目錄樹來管理文件�,并提供傳統(tǒng)的Create、Delete����、Open�����、Close��、Read和Write操作��。除此之外�,GFS還專門提供了Snapshot和Record Append兩種操作�。其中Snapshot以最小的開銷創(chuàng)建一個目錄或文件的副本,Record Append則用來保證多個應(yīng)用程序同時對文件進行追加寫操作時的正確性���。
GFS采用了怎樣的系統(tǒng)架構(gòu)?
如圖1所示�����,一個GFS的集群包括一個主服務(wù)器(master)和多個塊服務(wù)器(chunk server),能夠同時為多個客戶端應(yīng)用程序(Application)提供文件服務(wù)���。每個服務(wù)器或應(yīng)用程序都是運行在Linux服務(wù)器中的一個進程�,只要性能允許���,可以將服務(wù)器進程和應(yīng)用進程運行在同一個物理服務(wù)器上�����。
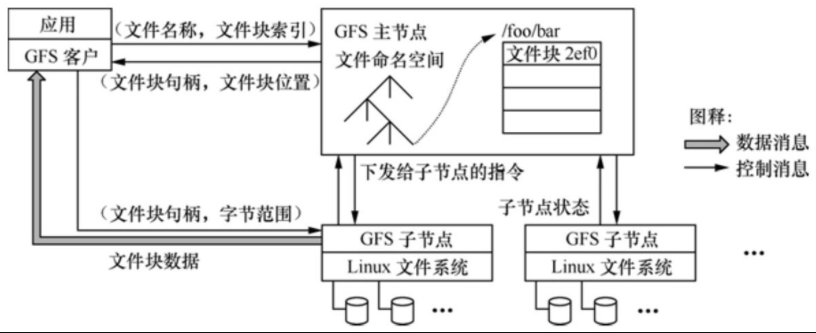
圖1 GFS的系統(tǒng)架構(gòu)
GFS中文件劃分為固定大小的塊�,每個塊在創(chuàng)建時由主服務(wù)器分配一個64位的句柄。塊服務(wù)器將塊以Linux文件的形式保存在本地硬盤上���,并通過句柄實現(xiàn)對其指定的字節(jié)范圍進行讀寫的操作����。缺省情況下����,GFS對每個塊在三個不同的塊服務(wù)器上保持三個備份,用戶也可定制備份策略���。
主服務(wù)器負責(zé)維護所有文件系統(tǒng)的元數(shù)據(jù)���,包括命名空間、存取控制信息�、文件和塊的映射關(guān)系以及塊的物理位置等。主服務(wù)器還負責(zé)管理文件系統(tǒng)�����,包括塊的租用、垃圾塊的回收以及塊在不同塊服務(wù)器之間的遷移�����。此外���,主服務(wù)器還周期性地與每個塊服務(wù)器通過心跳消息交互�,以監(jiān)視運行狀態(tài)或下達命令����。應(yīng)用程序采用GFS提供的API函數(shù)接口通過與主服務(wù)器和塊服務(wù)器的交互來實現(xiàn)對應(yīng)用數(shù)據(jù)的讀寫,應(yīng)用與主服務(wù)器之間的交互僅限于元數(shù)據(jù)�����,所有的數(shù)據(jù)操作都是直接與塊服務(wù)器交互的���。
GFS中應(yīng)用和塊服務(wù)器都沒有針對數(shù)據(jù)采用緩存機制����。絕大多數(shù)應(yīng)用的流數(shù)據(jù)都是大型文件���,因此在客戶端無法采用數(shù)據(jù)緩存機制;而塊服務(wù)器在Linux文件中已經(jīng)采用了緩存機制����,因此也不需要重復(fù)實現(xiàn)塊的緩存了��。當(dāng)然��,客戶端針對元數(shù)據(jù)還是采取了緩存機制����。
塊的大小是如何設(shè)計的?
這是一個關(guān)鍵設(shè)計參數(shù),GFS選擇了64MB����,該方案優(yōu)點如下。
(1)降低了客戶與主服務(wù)器之間的交互�����。對于在同一塊之內(nèi)讀寫操作需要的塊服務(wù)器信息�����,客戶只需要向主服務(wù)器請求一次就可以了����,因此降低了客戶與主服務(wù)器之間的交互����。由于GFS的應(yīng)用大多是面向大文件的���,因此這個優(yōu)點體現(xiàn)得很明顯���。
(2)降低了集群中的網(wǎng)絡(luò)負荷。由于客戶的讀寫操作大多被限制在同一塊服務(wù)器之內(nèi)��,客戶就不需要建立與多個塊服務(wù)器的TCP連接����,因此降低了網(wǎng)絡(luò)負荷。
(3)減少了主服務(wù)器中元數(shù)據(jù)的存儲容量�����。該方案的缺點如下:如果多個客戶同時訪問一個僅有幾個塊組成的小文件的話����,存儲該小文件的塊服務(wù)器就會成為性能瓶頸。由于Google公司實際應(yīng)用中絕大多數(shù)操作都是對大數(shù)據(jù)文件的讀取�����,因此并沒有出現(xiàn)這樣的情況�。
GFS的讀操作是如何實現(xiàn)的?
讀操作的步驟如下。
(1)客戶根據(jù)指定位置和塊大小計算得到文件中的塊索引;
(2)客戶將文件名和塊索引發(fā)給主服務(wù)器查詢對應(yīng)的塊服務(wù)器及句柄;
(3)客戶將這些信息緩存在本地;
(4)客戶向最近的塊服務(wù)器發(fā)送讀請求��,包括塊句柄及讀取范圍;
(5)塊服務(wù)器返回客戶要求讀取的塊內(nèi)容�。GFS的寫操作又是如何實現(xiàn)的?
如圖2所示,寫操作包括7個步驟:
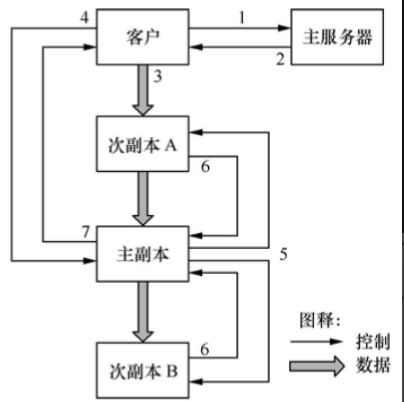
圖2 GFS的寫操作
(1)客戶向主服務(wù)器查詢寫入塊對應(yīng)的主副本及次副本所在的塊服務(wù)器�,主服務(wù)器通過租約從多個塊服務(wù)器中選擇主副本。
(2)主服務(wù)器向客戶返回寫入塊的位置信息��。
(3)客戶將寫入數(shù)據(jù)推送到所有副本上����,每個塊服務(wù)器將這些數(shù)據(jù)保存在內(nèi)部緩存中,直到數(shù)據(jù)被使用或過期�����。
(4)客戶向主副本所在的塊服務(wù)器發(fā)送寫請求���。
(5)主副本將客戶的寫請求傳遞到所有的次副本����。
(6)寫入完成后,各次副本將完成情況反饋給主副本�����。
(7)主副本將完成情況反饋給客戶�,如果出錯則重復(fù)(3)~(7)步驟。
HDFS的架構(gòu)是怎樣的?
如圖3所示���,一個HDFS的集群包括一個名稱節(jié)點(NameNode)和多個數(shù)據(jù)節(jié)點(DataNode)�����,能夠為多個客戶程序(Client)提供服務(wù)�����。HDFS采用Java語言開發(fā)���,因此任何支持Java的計算機都可以用來部署NameNode和DataNode。
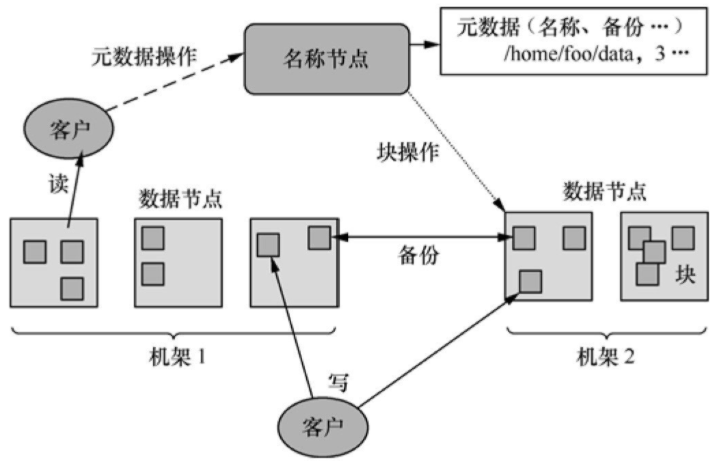
圖3 HDFS的架構(gòu)
HDFS內(nèi)部將文件劃分為若干個數(shù)據(jù)塊�,每個文件都存儲為一系列的數(shù)據(jù)塊,除最后一個外所有數(shù)據(jù)塊的大小是相同的��。缺省情況下����,HDFS同時保存每個數(shù)據(jù)塊的三個副本���。
NameNode管理文件系統(tǒng)的命令空間,并維護文件到數(shù)據(jù)塊的映射關(guān)系���。DataNode負責(zé)處理客戶程序的文件讀寫請求,并在NameNode統(tǒng)一調(diào)度下進行數(shù)據(jù)塊的創(chuàng)建�、復(fù)制和刪除工作。
大型的HDFS集群一般跨越多個機架�����,不同機架之間通過交換機通信���。一般將數(shù)據(jù)塊的不同副本存放在不同的機架上�����,這樣可以有效防止整個機架失效時數(shù)據(jù)的丟失�����,還可以在執(zhí)行讀操作時充分利用多機架的帶寬實現(xiàn)負載均衡�����。
HDFS的讀操作是如何實現(xiàn)的?
如圖4所示����,客戶程序通過調(diào)用FileSystem對象的open()方法打開希望讀取的文件DistributedFileSystem實例,后者通過遠程進程調(diào)用訪問NameNode得到文件起始塊的位置����。DistributedFileSystem實例返回一個輸入流FSDataInputStream對象給客戶程序以讀取數(shù)據(jù),該輸入流對象專門封裝一個DFSInputStream對象管理NameNode和DataNode�。
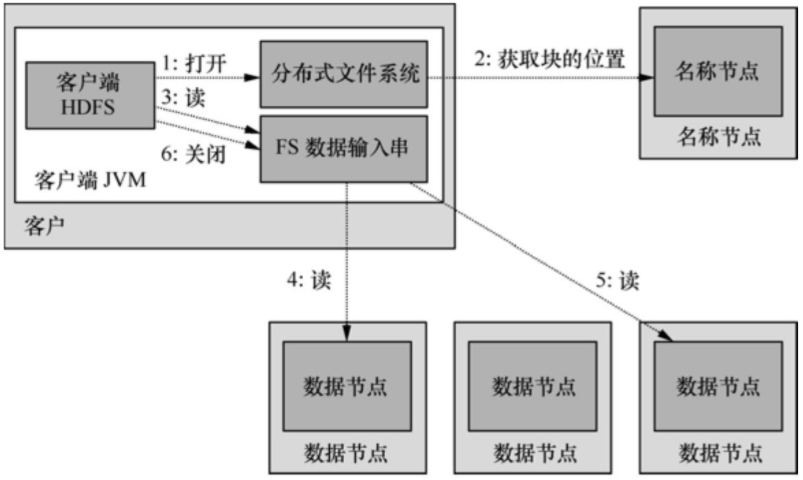
圖4 HDFS的讀操作
客戶程序?qū)υ撦斎肓鲗ο笳{(diào)用read()方法,DFSInputStream對象即連接到距離最近的DataNode����,通過反復(fù)調(diào)用read()就可以將數(shù)據(jù)塊從DataNode傳輸?shù)娇蛻舫绦颉5竭_塊的末端后���,DFSInputStream會關(guān)閉與該DataNode的連接����,轉(zhuǎn)而尋找下一個塊的最佳DataNode����。所有的數(shù)據(jù)塊都讀取完成后會調(diào)用FSDataInputStream對象的close()方法結(jié)束本次讀操作�。
HDFS的寫操作又是如何實現(xiàn)的?
如圖5所示�����,客戶程序通過對DistributedFileSystem對象調(diào)用create()方法來創(chuàng)建文件�,該對象同時對NameNode創(chuàng)建一個遠程進程進程調(diào)用,在文件系統(tǒng)的命名空間中創(chuàng)建新文件�。之后DistributedFileSystem向客戶程序返回一個FSDataOutputStream對象,由此客戶端開始寫入數(shù)據(jù)����。同時還會封裝一個DFSOutputStream對象負責(zé)管理NameNode和DataNode�����。
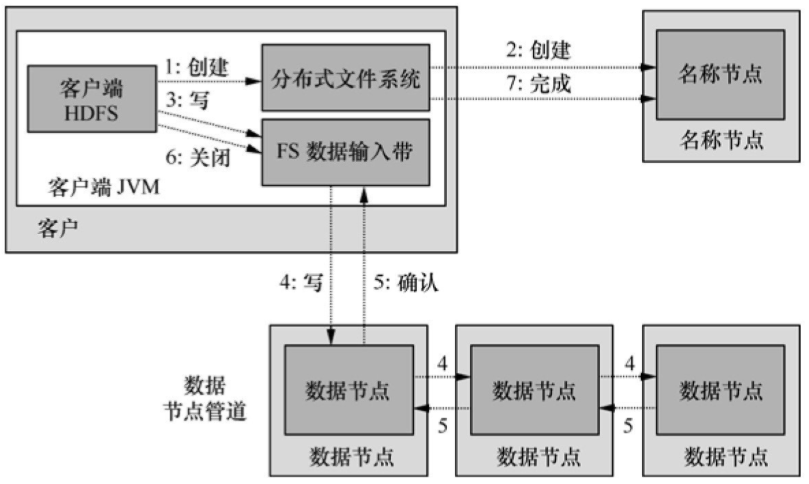
圖5 HDFS的寫操作
在數(shù)據(jù)寫入過程中�,DFSOutputStream將寫入數(shù)據(jù)劃分為多個數(shù)據(jù)包,并采用數(shù)據(jù)隊列方式向多個DataNode寫入副本����,收到確認消息后繼續(xù)上述過程寫入其他數(shù)據(jù)塊。所有數(shù)據(jù)塊寫入完成后會調(diào)用close()方法結(jié)束本次寫入操作�����,并通知NameNode。
看起來HDFS與GFS非常相似啊����,它們是什么關(guān)系呢?
Google在一份公開發(fā)布的論文中介紹了GFS的基本原理,但是并沒有公開其源代碼���,Hadoop開源項目參考GFS公開的設(shè)計文檔設(shè)計實現(xiàn)了HDFS���,所以兩者看起來是非常相似的。
一般認為HDFS是GFS的一個簡化版的實現(xiàn)�����,兩者有很多相似之處���,例如都采用單主服務(wù)器和多數(shù)據(jù)服務(wù)器的架構(gòu)�����、都采用數(shù)據(jù)塊的方式來組織和管理文件��。但是兩者還是有不少差異的���,例如HDFS不支持Record Append和Snapshot操作����。
上一篇:
HCIE-Routing & Switching切換HCIE-Datacom補充公告
下一篇:
什么是分布式系統(tǒng)














